¿Qué es Git?
Git es un sistema de control de versiones distribuido, es gratuito y de código abierto. Está diseñado para manejar desde proyectos pequeños hasta proyectos muy grandes, esto lo hace con velocidad y eficiencia. El control de versiones es un sistema que lleva registro de los cambios a un archivo o grupo de archivos a través del tiempo, lo que permite obtener versiones específicas en cualquier momento.
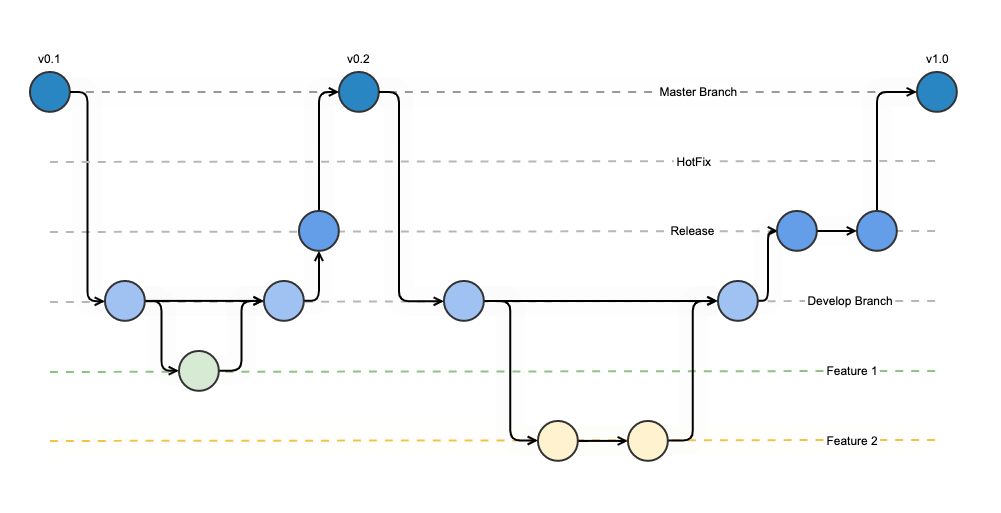
Cuando se trabaja con Git se necesita crear un repositorio, que es el espacio en donde residirá el proyecto. También branches (ramas), que son copias del repositorio y que cada branch se crean commits con cambios. Un commit es como una foto de cómo se encuentran el o los archivos en un momento determinado.
¿Por qué usar Git?
Frente a otros sistemas de control de versiones, Git presenta como ventajas que es fácil de aprender con un impacto pequeño en el desempeño de un sistema. Además, su característica casi única es la capacidad de crear branches, lo que equivale a que por ejemplo en un mismo ambiente de desarrollo se puedan tener múltiples líneas de trabajo totalmente independientes una de otra.
Esto es muy útil porque permite hacer cambios de contexto de forma fácil, crear roles para cada branch que satisfagan las distintas necesidades del proyecto. También permite trabajar en la implementación de más de una funcionalidad al mismo tiempo y así incluir el trabajo de esta progresivamente hasta que esté lista para ser incluida en el branch principal de desarrollo. Así mismo se puede trabajar en algo para efectos de prueba que finalmente no se va a incluir y simplemente borrarlo sin consecuencias para el repositorio.
Al ser distribuido, en lugar de bloquear elementos en el código fuente se genera una copia local del repositorio completo. Así se cuenta con muchos respaldos del código fuente. Gracias a esta característica y a la capacidad de crear múltiples branches se puede trabajar con distintos marcos de trabajo.
Por otro lado, Git también ofrece seguridad para los datos, pues su modelo asegura la integridad criptográfica de todo el proyecto. A cada archivo y cada commit se le aplica suma de verificación y cuando los archivos y los commits y cuando estos son obtenidos de vuelta en el repositorio (sea local o remoto), también se les aplica una suma de verificación. Esto hace imposible obtener piezas de información ajenas a lo que los usuarios del repositorio hayan enviado. Otra ventaja que ofrece este sistema es la capacidad de seleccionar cuáles cambios del total que se han hecho van a ser incluidos en un commit.
¿Cómo se usa Git?
Originalmente Git estaba pensado para ser usado con la línea de comandos, sin embargo, actualmente es posible integrar interfaces gráficas en los entornos de desarrollo.
Comandos básicos
Asumiendo que se va a trabajar en un repositorio previamente creado, los comando básicos que se necesitan son:
- git config –global user.name “{name}” y git config –global user.email {email}, se utilizan para configurar el usuario al que se le van a atribuir los commits.
- cd root se utiliza para posicionarse en un directorio, necesario para establecer en cual se va a clonar el repositorio.
- git clone {url} se utiliza para clonar el repositorio que se encuentra en la URL proporcionada.
- git checkout {branchName} comando utilizado para cambiar de branch, si se le agrega -b antes del nombre del branch, crea un branch con ese nombre siempre y cuando no exista otro igual. Para sobrescribir un branch existente se usa -B.
- git status este comando permite saber el estado del branch, indica cosas como si está actualizado con su contraparte remota, si hay cambios en los archivos, si se han incluido archivos para ser parte de un commit, entre otras cosas.
- git log permite ver la historia, es decir, los commits que se han hecho en orden descendente con el parámetro -p muestra los cambios introducidos en cada commit y con -{number} se le indica el número de registros que van a ser devueltos.
- git add/rm {fileName} agrega o elimina un archivo para ser parte de un commit.
- git stash en lugar de agregar los archivos para el commit este comando permite ocultar los archivos para que no se detecten sus cambios, para mostrar los cambios el comando es git stash pop.
- git diff muestra los cambios en los archivos que no han sido incluidos para ser parte de un commit, si se desean mostrar los cambios para esos, se incluye el parámetro —staged.
- git commit muestra un editor para escribir un mensaje que servirá para indicar de qué se tratan los cambios, si no se quiere abrir el editor se puede agregar como parámetro -m “{text}” para escribir el texto directamente.
- git commit –amend permite editar el mensaje de un commit y también funciona como git commit abriendo el editor o escribiendo el mensaje directamente, además si se ejecuta el comando git add después de
- git commit también va a incluir el commit más reciente, los archivos que acaban de ser agregados.
git restore –staged {fileName} (previamente reset HEAD {file}) este comando hace lo contrario que git add y permite remover un archivo de la lista de los archivos que van a ser parte del próximo commit. Se puede sustituir HEAD por un commit específico, pero esto cambia la historia. - git restore {fileName} (previamente git checkout — {file}) deshace los cambios hechos en el archivo indicado, siempre y cuando el archivo no haya sido usado con git add, si se hizo eso, entonces es necesario ejecutar el comando anterior.
- git push <remote> <branch> envía los cambios del branch local al branch remoto indicado
- git fetch descarga todos los cambios hechos en el repositorio remoto que no se encuentran en el repositorio local, pero no los aplica.
- git merge comando para incorporar los cambios de un branch en otro.
- git pull descarga los cambios y además, si no hay conflictos, los aplica a los archivos en el branch actual, es decir, ejecuta un git fetch seguido de un git merge.
- git rebase {branchName} conserva los commits del branch actual y reemplaza los anteriores con los commits del branch.
- git branch con el parámetro -m {name} se renombra un branch, con el parámetro -d {name} se borra un el branch especificado.
Soluciones a algunos problemas
Si varias personas de un equipo están trabajando en un mismo repositorio llevando a cabo distintas tareas, que pueden estar o no relacionadas con las de los demás, existe el riesgo de cometer errores en el manejo de los branches. Además, si no se establece un flujo de trabajo claro, el riesgo es mayor. Para esto Git cuenta con tres comandos que permiten reescribir la historia.
El primer escenario ocurre cuando se necesita hacer un despliegue (deployment) a producción de cambios que se encuentran en un branch pero no se puede publicar el branch en su totalidad. En este caso se necesita crear un branch usando como base el último branch que se desplegó a producción y entonces traer a este branch los commits necesarios. Para esto se usa el comando git cherry-pick {commitId} y si no hay ningún conflicto, entonces aplicará el cambio al branch.
El segundo escenario es cuando por error se incorporaron commits en un branch y se necesita deshacer los cambios que se aplicaron, en este caso git revert {commitId} y esto creará un commit nuevo que deshace los cambios hechos en los archivos por el commit suministrado.
El tercer y último escenario a tratar es el más complejo. Consiste en que se incorporaron muchos cambios en un branch por error, por ejemplo de otras funcionalidades, estos no están ordenados, fueron hechos en distintas fechas y/o por distintas personas, dejando una sucesión larga de commits. En este caso la solución es utilizar un rebase interactivo. Para esto primero se necesita identificar aquellos commits que se deben quedar y los que se deben eliminar.
Con git rebase -i {commitId} se indica a partir de qué commit se necesita traer la historia. Un editor se abrirá mostrando líneas con el formato pick commitId commitMessage, se debe ir uno por uno y cambiar pick por drop en aquellos commits que se desee eliminar de la historia del branch, o por edit en aquellos donde se quiere cambiar el mensaje. Algunas veces no es posible el rebase interactivo por la forma en cómo fueron hechos los commits, por ejemplo que uno que se desea conservar tiene como base uno que se quiere borrar.
Revisión de código
En el trabajo colaborativo en un repositorio es necesario que los pares revisen el código que cada miembro quiere incluir en los branches comunes del proyecto. Por ejemplo el branch que se usa para el despliegue a producción debe ir libre de errores. Para esto es necesario la creación de los pull requests, depende del servicio que se use la forma como se haga varía, pero esencialmente consiste en una solicitud donde se indica hacia qué branch se quiere hacer el merge, automáticamente se listan los commits que existen en el branch que no existen en el branch destino (base) y las personas a las que se les solicita la revisión.
